Context utilization tracks how much of Claude’s context window is consumed during a conversation. The context window is the total amount of information (your messages, the AI’s responses, code, files, and system instructions) that gets sent to the model provider with each message. Claude itself doesn’t store anything locally — all context is managed server-side, which means the main impact of context size is on cost and response speed.
How Context Grows
The most important thing to understand about context is that it grows exponentially, not linearly. Every time you send a new message, the model provider receives the entire conversation history — not just your new message, but all previous messages combined. For example, sending your 100th message means the provider processes all 100 messages at once.

This has two practical consequences:
- Cost scales exponentially — each additional message makes every subsequent message more expensive, since all previous content is re-sent each time.
- Attention degrades — the larger the context, the less attention the model pays to each part of it. This means the model can appear to “forget” things you said earlier or overlook details in your instructions, effectively getting dumber as the conversation grows.
For these reasons, it’s best to avoid unnecessarily long chats. Start new tasks in fresh chats rather than piling everything into one conversation.
Token Metrics
Each message in a conversation contributes tokens to the context. The key metrics are:

- Input tokens — tokens in the prompt sent to the API (your message plus any code, files, or context)
- Cache read tokens — tokens served from the prompt cache (reused from previous turns, much cheaper than fresh input)
- Output tokens — tokens generated in the AI’s response
- Context tokens — the total context consumed per message:
cacheReadTokens + inputTokens - Context limit — the maximum context window size, defined server-side by the model provider. The
MODEL_CONTEXT_LENGTHenvironment variable controls only what’s shown in the progress bar and charts — set it to match your model’s actual limit for accurate readings - Utilization percentage — how much of the context window has been used:
(totalUsed / contextLimit) × 100
Cost Tracking
Xedant Code calculates and displays cost at three levels:
- Per-message — each AI response shows its cost in the message metadata (visible when message tokens are displayed). Cost is calculated from the actual token counts of that message using the pricing of the active environment.
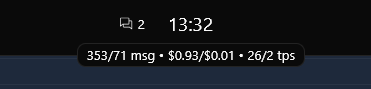
- Per-chat — the chat stats badge at the top of the chat view shows the running total cost for the current conversation. Hover over it to see a breakdown of message count, cost, tokens per second, and token details (cache, input, output).
- Recent stats (header) — the stats badge in the page header shows aggregated cost across all chats within a configurable time range. It displays the total number of prompts, total cost, and average tokens per second. Click it to change the time range (today, last 7 days, this month, etc.) or open the full Analytics page.


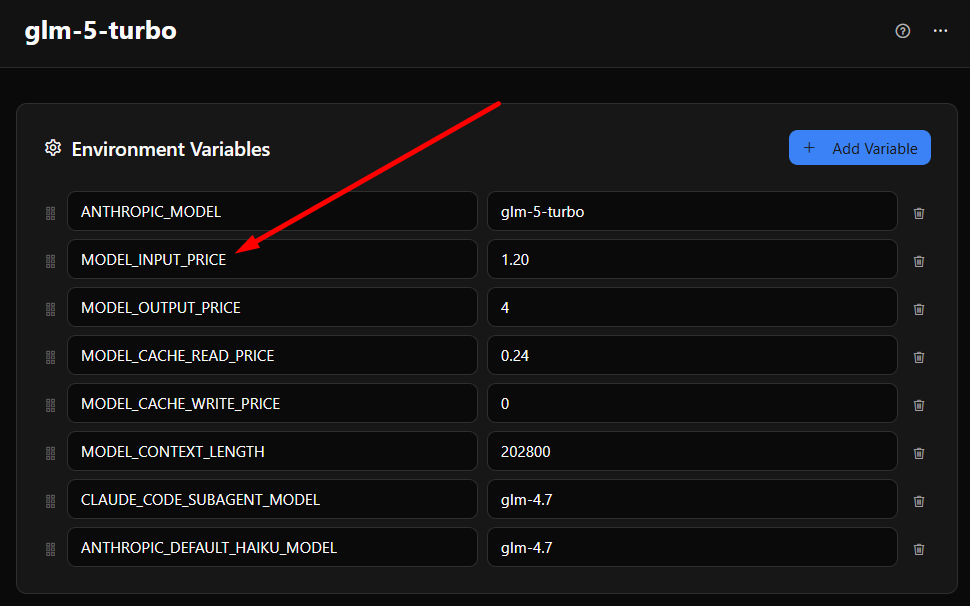
Cost is calculated using four pricing variables from the active environment: MODEL_INPUT_PRICE, MODEL_OUTPUT_PRICE, MODEL_CACHE_READ_PRICE, and MODEL_CACHE_WRITE_PRICE — all in USD per million tokens. If not set, these defaults are used:
MODEL_INPUT_PRICE— $0.60MODEL_OUTPUT_PRICE— $2.20MODEL_CACHE_READ_PRICE— $0.11MODEL_CACHE_WRITE_PRICE— $0
These defaults are based on typical Chinese model pricing (e.g. GLM 4.7), not Anthropic’s list prices. If you’re using Anthropic Claude or another provider, these numbers won’t match. You can set model-specific pricing per environment using the Environments page — environments are hierarchical, so you can define shared variables like API endpoint and access key once in a parent environment, then set per-model pricing in child environments without repeating them. Resolution order: environment variables → system configuration → hardcoded defaults.
Keep in mind that these calculations show what requests would cost at API pay-per-token rates. In practice, most users subscribe to coding plans (Anthropic Max, GitHub Copilot, etc.) which are 10–30× cheaper. Beyond that, real pricing is far more complex than a simple per-million-token rate — providers may apply different pricing depending on time of day, usage volume, context size, and various discounts or penalties. For this reason, the cost numbers in Xedant Code are only rough estimates useful for comparing relative request weight and spotting unusually expensive chats. Your provider’s billing or account page is the only source of truth — check it regularly.
Context Chart Dialog
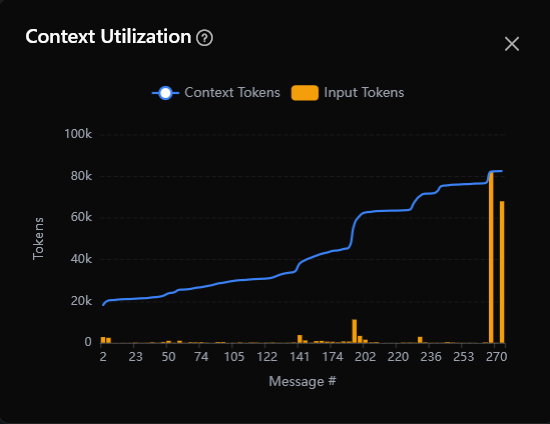
The context utilization chart visualizes token usage across the conversation. Open it by clicking the context indicator in the chat header. The chart shows two data series:
- Context Tokens (blue line) — the total context consumed per message, shown as a smoothed line. This combines cached tokens and fresh input tokens.
- Input Tokens (orange bars) — the fresh input tokens per message, shown as vertical bars. These represent tokens not served from cache.
The X-axis represents message numbers (1, 2, 3…) and the Y-axis shows token counts. Values above 1,000 are displayed in abbreviated form (e.g., “50k”). Messages with zero context tokens are filtered out of the chart.
Reading the chart: a rising blue line means the AI is consuming more context over time — typically because each message includes previous messages plus the growing conversation history. Orange bars show where fresh (non-cached) tokens are being used, which indicates new content being added rather than reused.
Context Limit
The actual context limit is defined server-side by the model provider and cannot be changed on your end. The MODEL_CONTEXT_LENGTH environment variable only controls the display — the progress bar and charts in Xedant Code. Set it to match your model’s actual context window size so the percentage and chart reflect reality. If not set, it defaults to 200,000 tokens.
Common context limits by model:
- Claude Opus 4.7 / Sonnet 4.6 — 200,000 tokens
- Claude Haiku 4.5 — 200,000 tokens
- Third-party models — varies; set
MODEL_CONTEXT_LENGTHto match the provider’s actual limit
When switching environments, the display updates automatically based on the new environment’s MODEL_CONTEXT_LENGTH value.
Managing Context Usage
Here are strategies for keeping context usage under control:
- Start new chats for new topics — each chat starts with a fresh context window. Instead of one long conversation covering multiple topics, start a new chat when you shift focus. This is the single most effective strategy.
- Monitor the chart — check the context chart periodically. If you see the utilization climbing steeply, consider wrapping up the current task and starting a new chat.
Auto-Compaction
When context hits about 70% of the limit, Claude Code automatically compacts it. Compaction replaces the full conversation history with a short summary generated by the model, freeing up space for new messages.
While compaction lets a conversation continue, it comes with significant drawbacks:
- Information loss — the summary is a lossy abstraction of the full history. Nuance, specific instructions, and contextual details get flattened or dropped entirely.
- Misleading summaries — the model may summarize your intent or instructions incorrectly, and subsequent responses will be based on that distorted understanding rather than what you actually said.
- Visible disruption — you’ll notice compaction events when the model suddenly tries to re-understand what you’re doing from scratch, or asks questions about things already discussed.
When you see compaction happening, the best course of action is to start a fresh chat. The model can re-discover project context from files, CLAUDE.md, and memory far more accurately than any summary could provide. A fresh start with clean context is almost always better than continuing after compaction.